
情感分析
- 无权重。直接计算文本中正、负情感词出现的次数
- 有权重。tf-idf, tf是词频,idf是权重。
Tfidf法
scikit库除了CountVectorizer类,还有TfidfVectorizer类。TF-IDF这个定义相信大家应该已经耳熟能详了:

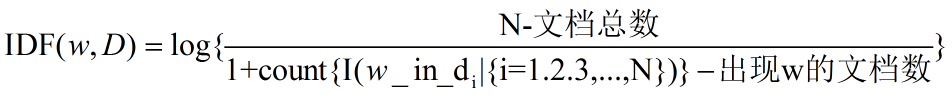
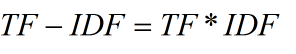
- TF 词语出现越多,这个词越有信息量
- IDF 词语越少的出现在文本中,词语越有信息量。
原始数据
import pandas as pd
corpus = ["hello, i am glad to meet you",
"it is wonderful",
"i hate you",
"i am sad"]
df1 = pd.DataFrame(corpus, columns=['Text'])
df1

构造tfidf
from sklearn.feature_extraction.text import TfidfVectorizer
def createDTM(corpus):
"""构建文档词语矩阵"""
vectorize = TfidfVectorizer()
#注意fit_transform相当于fit之后又transform。
dtm = vectorize.fit_transform(corpus)
#vectorize.fit(corpus)
#dtm = vectorize.transform(corpus)
#打印dtm
return pd.DataFrame(dtm.toarray(),
columns=vectorize.get_feature_names())
df2 = createDTM(df['text'])
df2
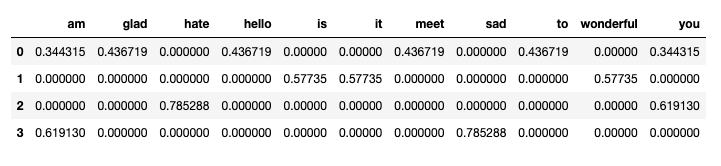
合并df1和df2
df = pd.concat([df1, df2], axis=1)
df

#积极词典
pos_words = ['glad', 'hello', 'wonderful']
#消极词典
neg_words = ['sad', 'hate']
#积极词典
df[pos_words]
df[pos_words].sum(axis=1)
Run
0 0.873439
1 0.577350
2 0.000000
3 0.000000
dtype: float64
df['Pos'] = df[pos_words].sum(axis=1)
df
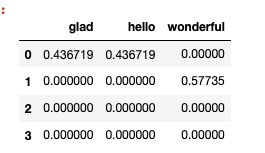
df['Neg'] = df[neg_words].sum(axis=1)
df

输出
df.to_csv('output/tfidf有权重的情感分析.csv')