代码下载
Stargazer库介绍
R语言有一个stargazer包,可用于创建漂亮的、可发表的多元回归表。如今有Python化的stargazer库也可做类似的事。
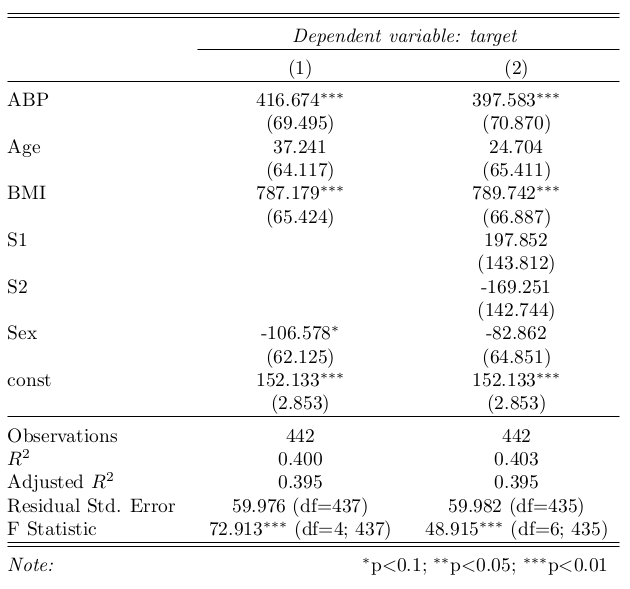
下图是使用stargazer生成的没有任何样式的原始示例的示例:
什么时候会用到这些?
人们倾向于使用R版本的stargazer的主要情况是在学术论文中报告回归结果。 它允许您轻松地比较多个回归结果,这有助于比较具有实验影响的模型与没有影响的模型之间的结果。 这允许用户轻松查看系数的差异、统计显着性以及实验引入的新变量的影响。
它目前支持 LaTeX 和 HTML 输出,stargazer开发者最终最表是也支持 Markdown 和 ASCII 文本。
项目地址
https://github.com/mwburke/stargazer
该库实现了原始包中的许多自定义功能。大多数示例可以在示例 jupyter notebook 中找到,功能函数完整列表如下:
Stargazer库的函数
- show_header:显示或隐藏模型头数据
- show_model_numbers:显示或隐藏型号
- custom_columns:自定义模型名称和模型分组
- significance_levels:更改统计显着性阈值
- significant_digits:更改有效数字的数量
- show_confidence_intervals:显示置信区间,而不是方差
- dependent_variable_name:重命名因变量
- rename_covariates: 重命名协变量
- covariate_order:重新排序协变量
- reset_covariate_order:将协变量顺序重置为原始顺序
- show_degrees_of_freedom:显示或隐藏自由度
- custom_note_label:表格底部的标签注释部分
- add_custom_notes:将自定义注释添加到表格底部的部分
- add_line:向表格中添加自定义行
- append_notes:显示或隐藏统计显着性阈值
这些功能与渲染类型无关,无论用户以 HTML、LaTeX 等格式输出都将应用
安装
!pip3 install stargazer
OLS回归
import pandas as pd
from sklearn import datasets
import statsmodels.api as sm
from stargazer.stargazer import Stargazer
diabetes = datasets.load_diabetes()
df = pd.DataFrame(diabetes.data)
df.columns = ['Age', 'Sex', 'BMI', 'ABP', 'S1', 'S2', 'S3', 'S4', 'S5', 'S6']
df['target'] = diabetes.target
est = sm.OLS(endog=df['target'], exog=sm.add_constant(df[df.columns[0:4]])).fit()
est2 = sm.OLS(endog=df['target'], exog=sm.add_constant(df[df.columns[0:6]])).fit()
stargazer = Stargazer([est, est2])
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/statsmodels/tsa/tsatools.py:142: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only
x = pd.concat(x[::order], 1)
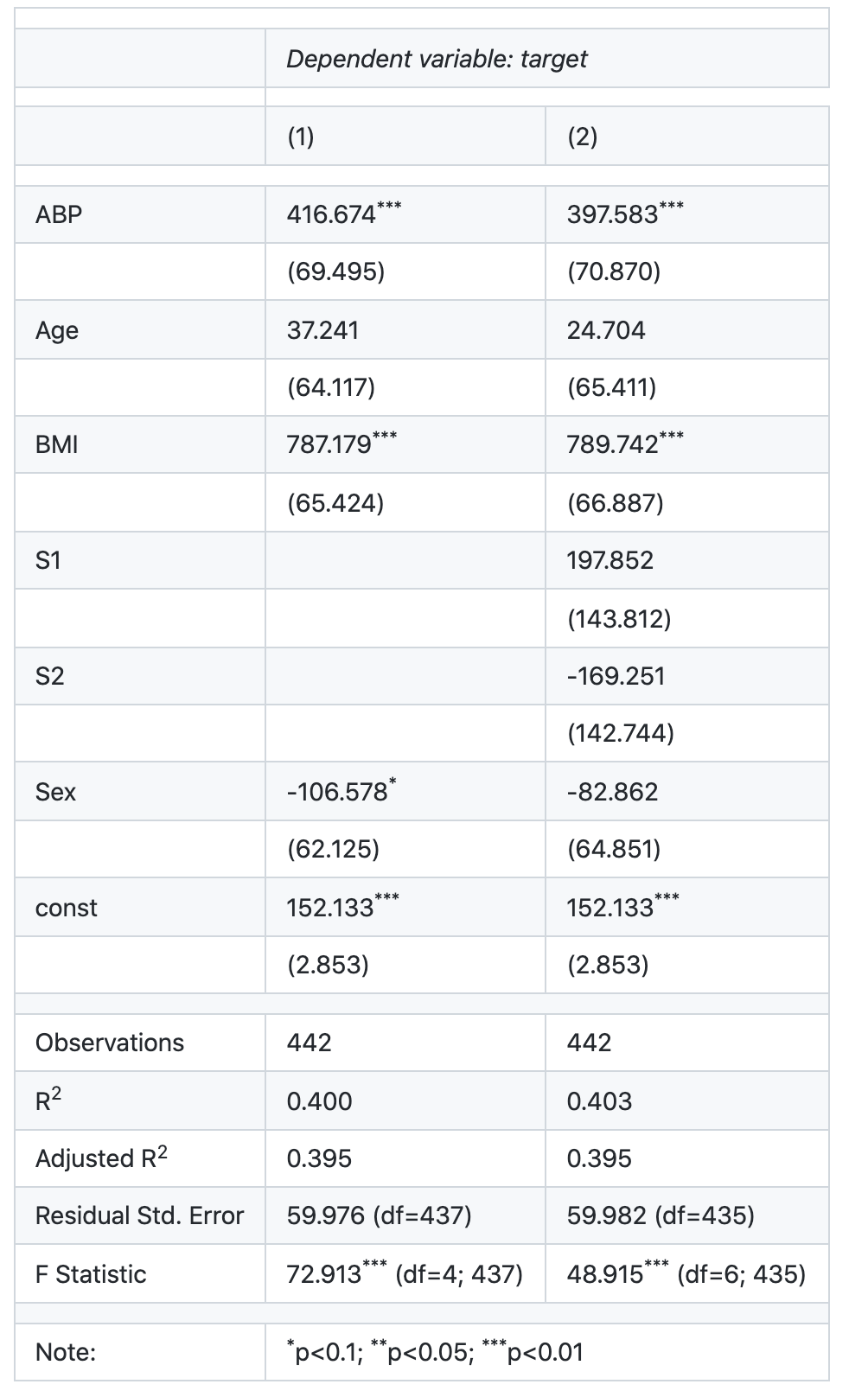
#分析结果渲染成html
from IPython.display import display, HTML
raw_str = stargazer.render_html()
html = HTML(raw_str)
display(html)
#分析结果渲染成latex
stargazer.render_latex()
了解课程
