
一、引言
社会文化是一个不断演变的复杂系统,受到历史、科技、经济和社会变革等多种因素的影响。随着时代的推移,人们的语言使用和文化认知也经历着变迁,反映着社会的发展脉络。在这个背景下,使用Word2Vec等词嵌入技术来研究社会文化变迁和刻板印象的重要性日益凸显。
Word2Vec作为一种词向量表示方法,通过将词汇映射到高维空间中的向量,有效地捕捉了词语之间的语义关系。这使得我们能够以全新的方式理解语言的演变和文化认知的转变。通过对比不同时期的Word2Vec模型,我们可以深入挖掘语言的时代特征,捕捉到文化观念、价值观念以及社会角色的演变。
研究社会文化变迁和刻板印象,不仅有助于解构历史时刻下的社会结构和文化动态,还能为我们提供深刻的洞察力,揭示出社会变迁中潜在的驱动力和趋势。这种研究有助于建构更为全面、客观的历史记忆,帮助我们更好地理解人类行为背后的深层次原因。
二、训练模型
2.1 获取数据
新闻数据集 | 含 人民日报/经济日报/光明日报 等 7 家媒体(2023.12.18)
- 7家媒体数据集打包 1688 元, 加微信 372335839, 备注「姓名-学校-专业」。
- 人民日报数据集 1000 元, 加微信 372335839, 备注「姓名-学校-专业」。
数据是虚拟产品,一经售出,不再退还!
时间宝贵,请先阅读推文内容, 再加微信详谈购买事宜
2.2 构造语料
本使用的 rmrb.csv.gz 对该数据集感兴趣的同学,可点击查看 新闻数据集 | 含 人民日报/经济日报/光明日报 等 7 家媒体(2023.12.18) 。
import pandas as pd
#读取人民日报rmrb.csv.gz,含1946-2023.12.08全部新闻文本
df = pd.read_csv('人民日报/rmrb.csv.gz', compression='gzip')
#每5年构造一个语料txt文件
for date, freq_df in df.groupby(pd.Grouper(key='date', freq='5Y')):
print(date)
with open(f'corpus/{date.year}.txt', 'a+', encoding='utf-8') as f:
text_series = freq_df['text']
text_series.fillna('', inplace=True)
f.write(''.join(text_series.tolist()))
Run
1946-12-31 00:00:00
1951-12-31 00:00:00
1956-12-31 00:00:00
1961-12-31 00:00:00
1966-12-31 00:00:00
1971-12-31 00:00:00
1976-12-31 00:00:00
1981-12-31 00:00:00
1986-12-31 00:00:00
1991-12-31 00:00:00
1996-12-31 00:00:00
2001-12-31 00:00:00
2006-12-31 00:00:00
2011-12-31 00:00:00
2016-12-31 00:00:00
2021-12-31 00:00:00
2026-12-31 00:00:00
语料txt命名规则, 实际上每个 year.txt 是存储了 year-5 ~ year 期间的新闻数据。
1946.txt内实际上只存储了1946.5.15 ~ 1946.12.31之间半年多的数据, 由于数据量太小,后续训练出的word2vec模型,其语义大概率不准。
2006.txt存储了 2002.1.1. ~ 2006.12.31 之间所有的数据
而2026.txt则存储了 2022.1.1 ~ 2026.12.31 之间所有的数据
2.3 训练word2vec
2.3.1 配置环境
使用 cntext2.1.0,未公开,需微信大邓 372335839 购买获取。 安装方法,将 cntext-2.1.0-py3-none-any.whl 放置于桌面, 打开命令行 cmd (mac是terminal), 依次执行
cd desktop
pip3 install cntext-2.1.0-py3-none-any.whl
cntext2.1.0 100元,已购买cntext2.0.0可免费更新。
2.3.2 开始训练
训练代码比较简单,已经封装到 cntext2.1.0, 只需几行代码即可。
训练环境win11, 内存126G,大家回去可以试试16G、32G,应该也能跑通。
import cntext as ct
import glob
#获取corpus文件夹内的所有语料txt文件的文件路径
corpus_files = sorted(glob.glob('corpus/*.txt'))
for corpus_file in corpus_files:
print(corpus_file)
w2v_model = ct.W2VModel(corpus_file=corpus_file,
lang='chinese')
w2v_model.train(window_size=6,
vector_size=200)
Run
corpus/1946.txt
Start Preprocessing Corpus...
Start Training! This may take a while. Please be patient...
Training word2vec model took 201 seconds
Note: The Word2Vec model has been saved to output/Word2Vec
......
......
corpus/2026.txt
Start Preprocessing Corpus...
Start Training! This may take a while. Please be patient...
Training word2vec model took 525 seconds
Note: The Word2Vec model has been saved to output/Word2Vec
三、检查模型
现在我们要检查模型, 为了方便,我就随机抽查 1946/1981/2001/2026, 查看这四个模型关于【工业】的近义词,看模型语义捕捉的准不准。
import cntext as ct
mfiles = ['output/Word2Vec/1946.200.6.bin',
'output/Word2Vec/1981.200.6.bin',
'output/Word2Vec/2001.200.6.bin',
'output/Word2Vec/2026.200.6.bin']
for mfile in mfiles:
w2v_model = ct.load_w2v(mfile)
print(mfile)
word_scores = w2v_model.wv.most_similar(['工业'], topn=20)
for word, score in word_scores:
print(word, score)
print()
Run
output/Word2Vec/1946.200.6.bin
[('物价', 0.9494231343269348),
('市场', 0.9431201815605164),
('对法', 0.937946081161499),
('商业', 0.931341290473938),
('投资', 0.9277867674827576),
('目前', 0.9103350043296814),
('农业', 0.9047650694847107),
('预算', 0.8974550366401672),
('计划', 0.8954270482063293),
('贸易', 0.8907712697982788),
('工商业', 0.8907474279403687),
('物资', 0.8891386389732361),
('重工业', 0.8887518048286438),
('估计', 0.8853818774223328),
('企业', 0.8833411931991577),
('规定', 0.8810412287712097),
('新五年计划', 0.8747104406356812),
('汽车厂', 0.8744568824768066),
('赔款', 0.8743201494216919),
('公司', 0.8725109100341797)]
output/Word2Vec/1981.200.6.bin
[('工业发展', 0.7668374180793762),
('轻工业', 0.7516288161277771),
('建筑业', 0.7424570918083191),
('手工业', 0.7337162494659424),
('重工业', 0.7331458330154419),
('化学工业', 0.7137069702148438),
('工业部门', 0.7033809423446655),
('基础工业', 0.6979346871376038),
('钢铁工业', 0.6970150470733643),
('中小企业', 0.6947773098945618),
('电子工业', 0.6943748593330383),
('运输业', 0.6904694437980652),
('造船', 0.6898190975189209),
('加工工业', 0.6891008019447327),
('工业生产', 0.6863811612129211),
('大型企业', 0.6822050213813782),
('行业', 0.6812164783477783),
('新兴工业', 0.6808343529701233),
('机械工业', 0.6797270178794861),
('民用工业', 0.6783092021942139)]
output/Word2Vec/2001.200.6.bin
[('工业发展', 0.7881254553794861),
('纺织', 0.749681830406189),
('重工业', 0.7422634959220886),
('制造业', 0.7263922095298767),
('产业', 0.720117449760437),
('汽车工业', 0.717221736907959),
('军工', 0.7118045687675476),
('工业部门', 0.7075888514518738),
('钢铁汽车', 0.6994239091873169),
('化工', 0.6939695477485657),
('化学工业', 0.6878121495246887),
('支柱产业', 0.6853876709938049),
('传统工业', 0.6830911636352539),
('纺织业', 0.6762925386428833),
('轻工业', 0.6752256155014038),
('传统产业', 0.6697835922241211),
('冶金', 0.6670747995376587),
('高科技产业', 0.666153073310852),
('石油化工', 0.6655437350273132),
('机械工业', 0.6599630117416382)]
output/Word2Vec/2026.200.6.bin
[('新材料', 0.7669156193733215),
('冶金', 0.7581453323364258),
('化工', 0.7405549883842468),
('高端装备', 0.7401999235153198),
('装备制造', 0.7394130229949951),
('石化', 0.7376166582107544),
('制造业', 0.711894154548645),
('半导体', 0.7055253386497498),
('制造', 0.7007594108581543),
('能源', 0.6951915621757507),
('智能制造', 0.6938720941543579),
('生物技术', 0.6936888694763184),
('矿业', 0.6906037330627441),
('核技术应用', 0.6892902255058289),
('新一代信息技术', 0.6885871887207031),
('精细化工', 0.6876311898231506),
('智能装备', 0.6843942999839783),
('石油化工', 0.6837282776832581),
('先进材料', 0.6828972101211548),
('风能', 0.6827014684677124)]
1946因为数据量较少,语义捕捉的没有后面三个准,但也大差不差的。 后面的分析中,我们就都使用对齐算,对word2vec模型进行语义对齐。
四、对齐模型
4.1 为什么要进行对齐?
Word2Vec是一种词嵌入(word embedding)算法,它将词语映射到高维空间中的向量,使得语义相近的词在该空间中距离较近。然而,不同年份的Word2Vec模型在训练时可能受到不同的语料库、训练参数等因素的影响,导致它们的向量空间之间存在一定的差异,所以不能直接拿不同年年份模型直接进行语义比较。
Procrustes对齐算法目的是通过线性变换来使两个向量空间尽可能地对齐,以便进行比较。这个过程涉及到对两个向量空间进行旋转、缩放和平移等变换,使它们在某种意义上尽量一致。
具体原因包括:
- 词汇漂移(Lexical Drift): 随着时间的推移,词汇的含义和使用可能发生变化,导致不同年份的语料库中的词语存在一定的漂移。Procrustes分析可以在一定程度上对齐这种漂移。
- 训练参数不同: Word2Vec模型的训练参数,如窗口大小、迭代次数等,可能在不同年份有所不同,导致生成的向量空间差异较大。
- 语料库的差异: 不同年份的语料库可能覆盖的主题、文体等存在差异,这也会影响词向量的学习结果。
通过Procrustes对齐,可以在一定程度上解决这些问题,使得不同年份的Word2Vec模型在语义上更具可比性。这有助于在跨时间的语料库中进行一致的语义分析。
4.2 对齐之后
对齐后的Word2Vec模型进行的语义变迁研究:
- 词义演变: 比较不同年份相同词汇的词向量,观察其在向量空间中的位置变化,分析词义在语义空间中的演变趋势。
- 语境变迁: 考察同一词语在不同年份的上下文中的变化,了解词语在不同语境下的语义演变情况。
- 主题变迁: 通过对齐后的向量空间,分析不同年份语料库中词语的主题分布变化,探讨社会、文化因素对语言使用的影响。
- 时代特征分析: 通过对比不同年份的模型,识别出每个时期在词向量空间中的独特特征,从而揭示时代背景对语义的影响。
- 探索新兴词汇: 通过对比不同年份的模型,发现在语义空间中新兴词汇的出现和演变,了解新兴概念和文化趋势。
总的来说,通过对齐Word2Vec模型,你可以更准确地比较不同年份的语料库,深入研究语义的演变和语言使用的变迁。这有助于揭示社会、文化、科技等方面的发展对语言表达的影响。
4.3 对齐代码
使用 cntext2.1.0,未公开,需微信大邓 372335839 购买获取。
import cntext as ct
#基准模型
base_embed = ct.load_w2v('output/Word2Vec/2026.200.6.bin')
#将其他模型与基准模型对齐
for file in mfiles:
print(file)
other_embed = ct.load_w2v(file)
procrusted_w2v = ct.procrustes_align(base_embed=base_embed,
other_embed=other_embed)
year=file.split('/')[-1][:4]
procrusted_w2v.save(f'output/Aligned_Word2Vec/{year}.200.6.bin')
Run
Loading word2vec model...
output/Word2Vec/1946.200.6.bin
Loading word2vec model...
16221 16221
16221 16221
output/Word2Vec/1951.200.6.bin
......
......
output/Word2Vec/2026.200.6.bin
Loading word2vec model...
14120 14120
14120 14120
五、实验-文化变迁
这里我演示 两个对立词组分别与目标词组进行语义距离计算, 根据语义距离反应刻板印象态度偏见,其实这也反映了文化变迁。
5.1 性别与成功
男性、女性与成功之间的语义距离
cntext2.1.0 内置了两种算法, 语义投影和语义距离,
distance = distance(女, 成功) - distance(男, 成功)
如果distance趋近于0, 男女在成功概念上语义接近, 无明显刻板印象。
但是当distance明显大于0, 当人们聊到成功概念时,更容易联想到男性,而不是女性。
import cntext as ct
import pandas as pd
import glob
gender_suceess_data = []
words = ['成功', '成就', '胜利']
c_words1 = ['女', '女人', '她', '母亲', '女儿', '奶奶']
c_words2 = ['男', '男人', '他', '父亲', '儿子', '爷爷']
mfiles = sorted(glob.glob('output/Aligned_Word2Vec/*.bin'))
for file in mfiles:
w2v = ct.load_w2v(file)
mind = ct.Text2Mind(wv=w2v.wv)
distance = mind.sematic_distance(words=words,
c_words1=c_words1,
c_words2=c_words2)
data = dict()
data['year'] = file.split('/')[-1][:4]
data['distance'] = distance
gender_suceess_data.append(data)
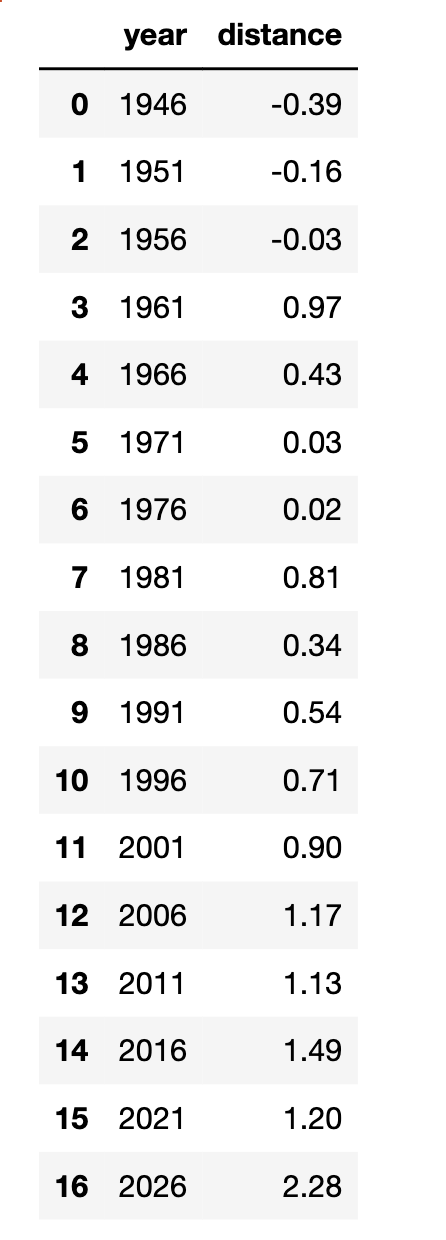
gender_success_df = pd.DataFrame(gender_suceess_data)
gender_success_df
import matplotlib.pyplot as plt
import matplotlib
import scienceplots
import platform
import pandas as pd
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
import jieba
import warnings
warnings.filterwarnings('ignore')
plt.style.use(['science', 'no-latex', 'cjk-sc-font'])
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
gender_success_df.set_index('year').plot(figsize=(10, 5), kind='bar')
plt.suptitle('人民日报在「成就」概念的文化变迁', size=15)
plt.xticks(rotation=0)
plt.title('大于0表示社会更容易将成功与男性联系起来')
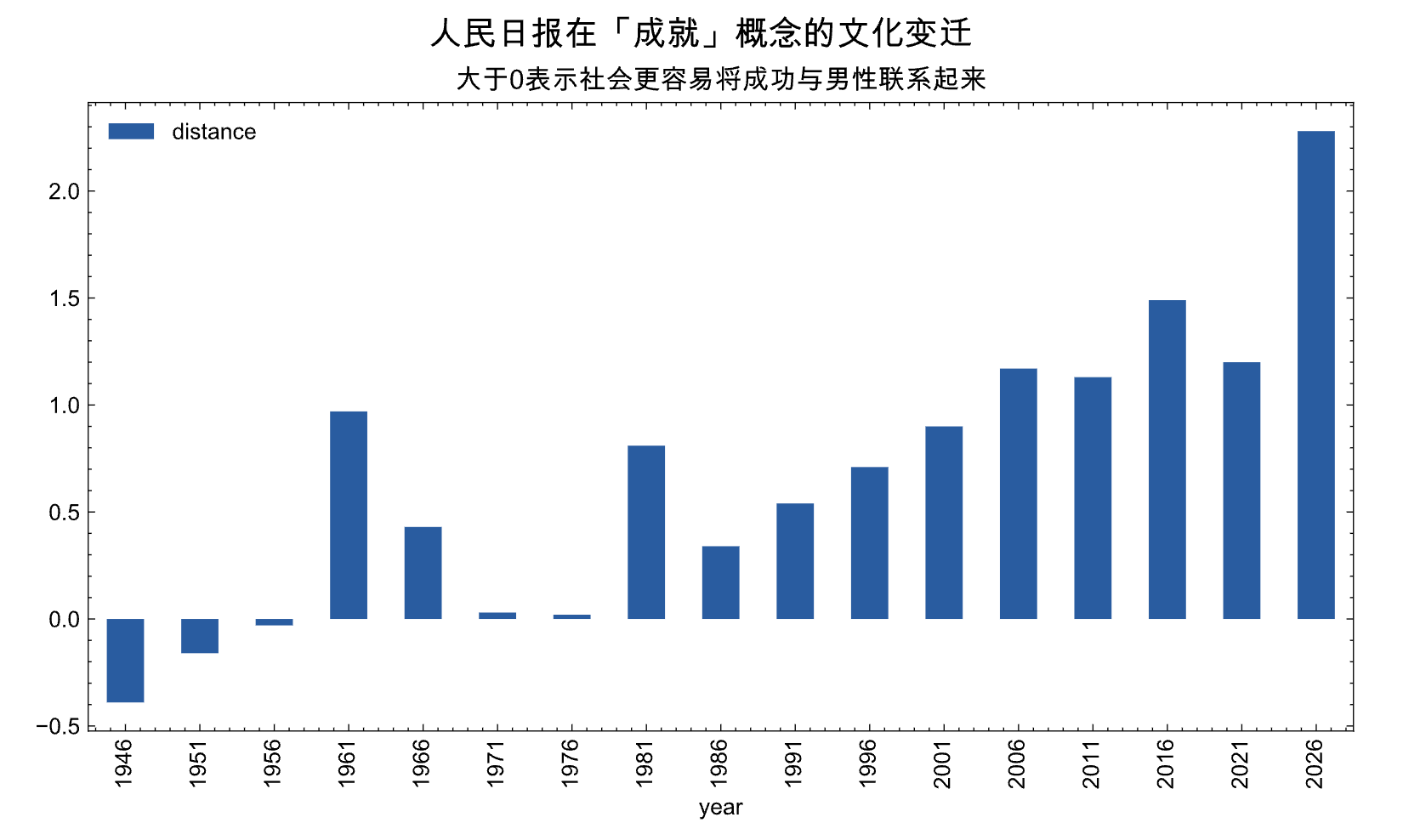
从图中可以看到, 新中国初期distance算法相对准确的刻画了那个时代的文化, 提到「成功概念」, 在「性别」联想区分度不大, 反映了那个时候宣传时候的中性, 立榜样考虑了性别的平衡。
即随着时间推移, 提到「成功概念」时,社会更容易将成功与「男性」联系起来。
从我的从小接受的教育, 在新中国初期, 宣传上很进步积极, 妇女撑起半边天 是那个激情年代的口号,也因此时至今日中国也是世界上女性就业率最高的国家。
5.2 性别与责任
成就与男性有更高的关联, 背后是否意味着传统文化建构的社会要求男性承担远多于女性的责任。
gender_responsibility_data = []
words = ['责任', '重担', '担当']
c_words1 = ['女', '女人', '她', '母亲', '女儿', '奶奶']
c_words2 = ['男', '男人', '他', '父亲', '儿子', '爷爷']
mfiles = sorted(glob.glob('output/Aligned_Word2Vec/*.bin'))
for file in mfiles:
w2v = ct.load_w2v(file)
mind = ct.Text2Mind(wv=w2v.wv)
projection = mind.sematic_projection(words=words,
c_words1=c_words1,
c_words2=c_words2)
distance = mind.sematic_distance(words=words,
c_words1=c_words1,
c_words2=c_words2)
data = dict()
data['year'] = file.split('/')[-1][:4]
data['distance'] = distance
gender_responsibility_data.append(data)
gender_responsibility_df = pd.DataFrame(gender_responsibility_data)
gender_responsibility_df.set_index('year').plot(figsize=(10, 5), kind='bar')
plt.xticks(rotation=0)
plt.suptitle('人民日报在「责任」语义的文化变迁', size=15)
plt.title('大于0表示社会更容易将「责任」与男性联系起来')
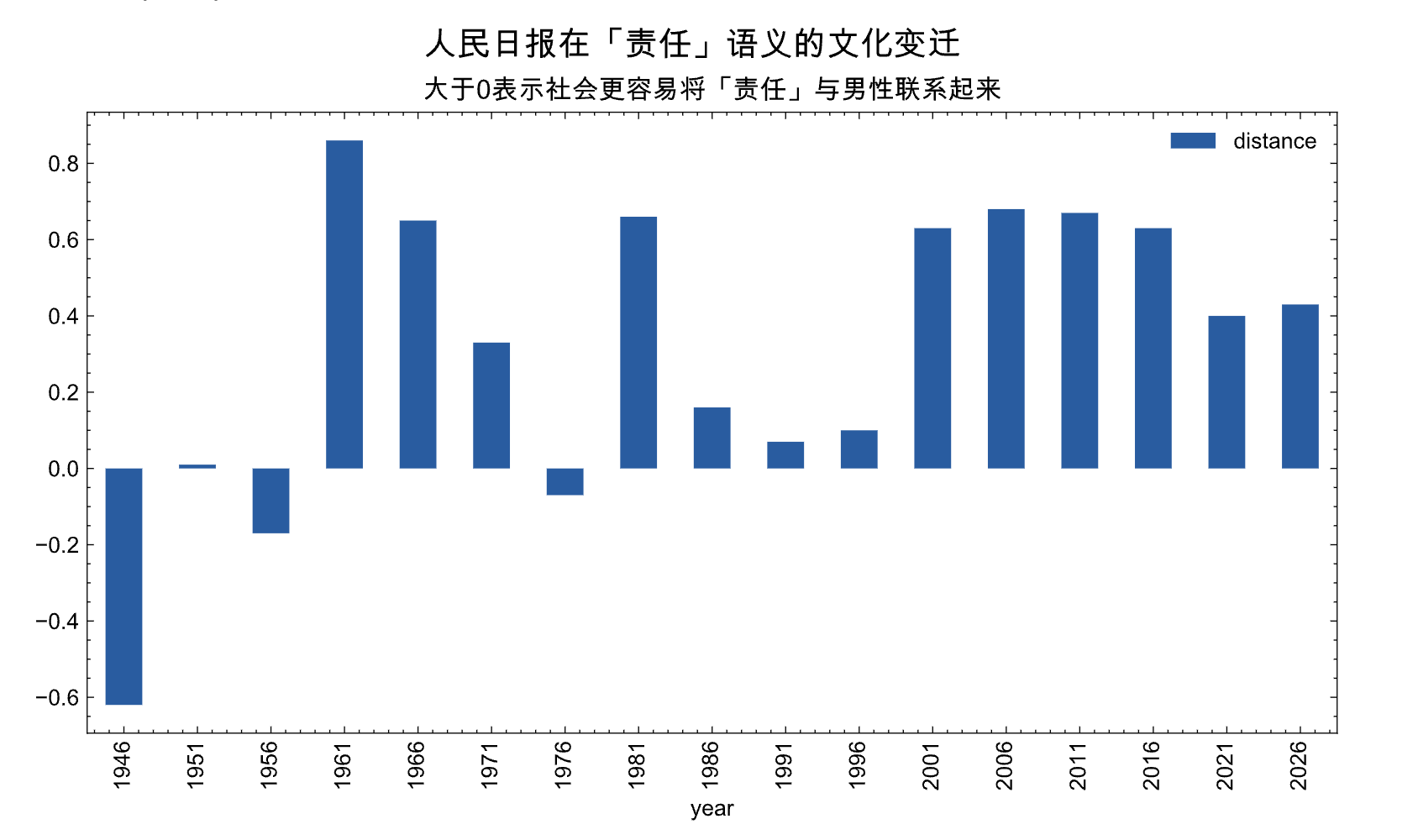
从图中可以看出,在大多数年份, distance是大于0的,即 提到「责任」概念时,社会更容易联想到「男性」,而不是「女性」。
五、相关
5.1 相关文献
[1]冉雅璇,李志强,刘佳妮,张逸石.大数据时代下社会科学研究方法的拓展——基于词嵌入技术的文本分析的应用[J].南开管理评论:1-27.
[2]Hamilton, William L., Jure Leskovec, and Dan Jurafsky. "Diachronic word embeddings reveal statistical laws of semantic change." arXiv preprint arXiv:1605.09096 (2016).
[3]Garg, Nikhil, Londa Schiebinger, Dan Jurafsky, and James Zou. "Word embeddings quantify 100 years of gender and ethnic stereotypes." Proceedings of the National Academy of Sciences 115, no. 16 (2018): E3635-E3644.
[3]Aceves, Pedro, and James A. Evans. “Mobilizing conceptual spaces: How word embedding models can inform measurement and theory within organization science.” Organization Science (2023).
[4]Kozlowski, A.C., Taddy, M. and Evans, J.A., 2019. The geometry of culture: Analyzing the meanings of class through word embeddings. American Sociological Review, 84(5), pp.905-949.
5.2 相关资料
- OS2022 | 概念空间 | 词嵌入模型如何为组织科学中的测量和理论提供信息
- 词嵌入技术在社会科学领域进行数据挖掘常见39个FAQ汇总
- 文献汇总 | 词嵌入 与 社会科学中的偏见(态度)
- 词向量 | 使用人民网领导留言板语料训练Word2Vec模型
六、获取资料
新闻数据集 | 含 人民日报/经济日报/光明日报 等 7 家媒体(2023.12.18)
- 7家媒体数据集打包 1688 元, 加微信 372335839, 备注「姓名-学校-专业」。
- 人民日报数据集 1000 元, 加微信 372335839, 备注「姓名-学校-专业」。
- cntext2.1.0 100元,已购买cntext2.0.0可以免费更新。
数据是虚拟产品,一经售出,不再退还!
时间宝贵,请先阅读推文内容, 再加微信详谈购买事宜