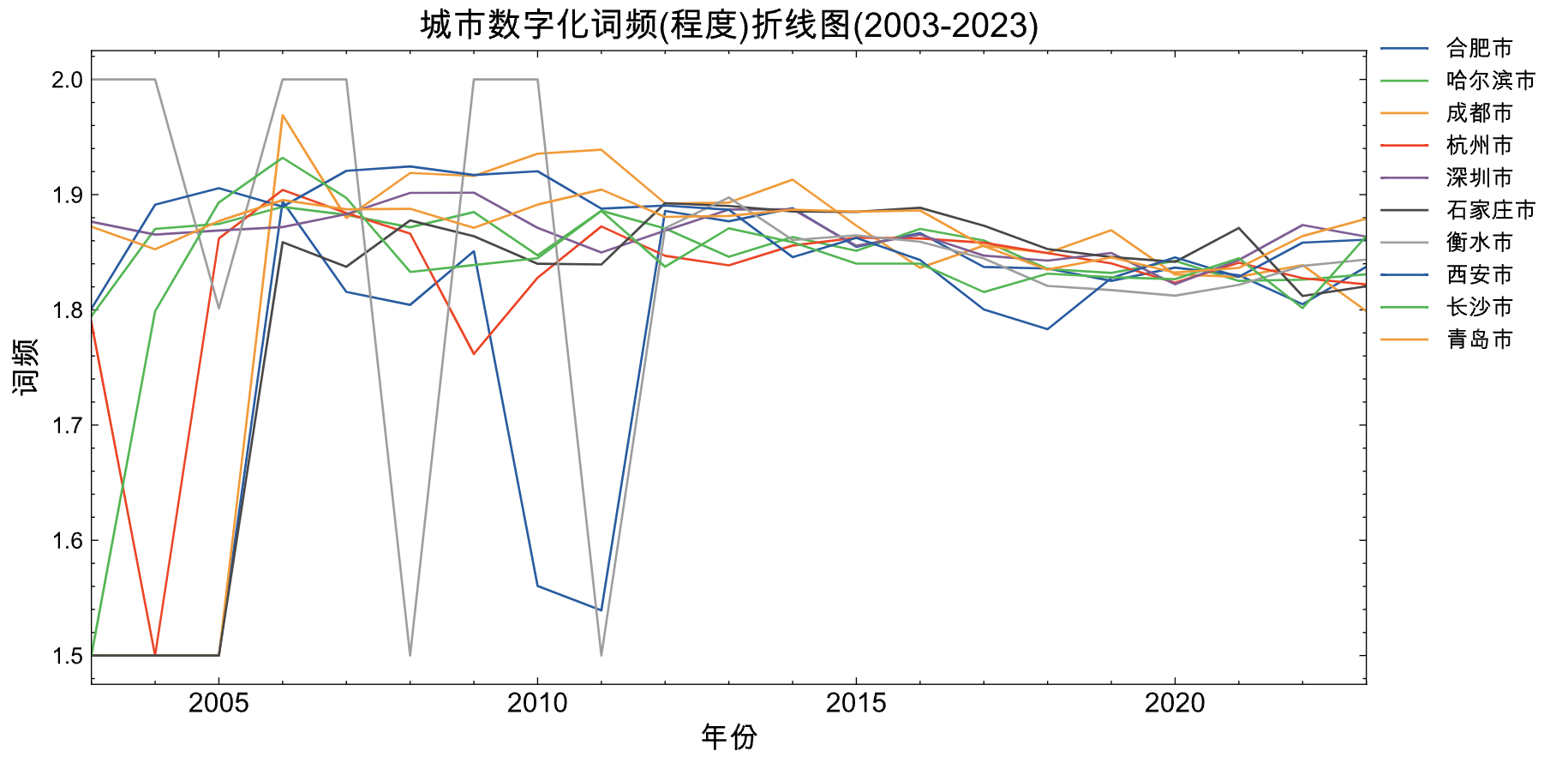
使用 10 个城市的2003-2023年的政府工作报告,绘制出的「数字化概念」词频的趋势图。 直接上效果效果图
相关代码
一、直接上代码
1.1 查看数据
数据集(付费) | 国、省、市三级政府工作报告文本 100元, 加微信 372335839, 备注「姓名-学校-专业」。
读取省报告数据文件 city_report2003-2023.csv ,点击链接,获取政府工作报告数据集
import pandas as pd
df = pd.read_csv('city_report2003-2023.csv')
df.head()

1.2 生成面板数据函数
假设你使用的城市政府工作报告数据是大邓提供的,可以直接使用下面封装的函数,快速生成概念词典,指定城市指定年度区间的面板数据。
def generate_panel_data(csvf, concept_words, selected_citys=None, selected_years=None):
"""
csvf: csv的文件路径
concept_words: 概念词词语列表
selected_citys: 筛选指定城市的数据进行计算,列表
selected_years: 筛选指定年度的数据进行计算,列表
结果返回dataframe, 每一行代表一个省,每一列代表一年。
"""
import pandas as pd
import jieba
df = pd.read_csv(csvf)
df['year'] = df['file'].apply(lambda f: f.split('/')[-1].replace('.txt', '')[-4:])
df['city'] = df['file'].apply(lambda f: f.split('/')[-1].replace('.txt', '')[:-4])
table_df = pd.pivot_table(df,
columns='year', #列-年份
index='city', #行-city
values='doc', #单元格-文本
aggfunc=lambda cs: ''.join(str(c) for c in cs)) #让单元格填充文本
if selected_citys:
table_df = table_df[table_df.index.isin(selected_citys)]
if selected_years:
selected_years = [str(y) for y in selected_years]
table_df = table_df[selected_years]
word_count_df = table_df.apply(lambda row: row.apply(lambda t: len(jieba.lcut(t))))
concept_word_count_df = table_df.apply(lambda row: row.str.count('|'.join(concept_words)))
concept_word_ratio_df = concept_word_count_df/word_count_df
return concept_word_ratio_df
#所有城市,所有年度(2002-2023)
panel_data_df = generate_panel_data(csvf='city_report2003-2023.csv',
concept_words = digitalization_words)
print(panel_data_df.shape)
#如果需要保存
panel_data_df.to_csv('文件路径2.csv', index=False)
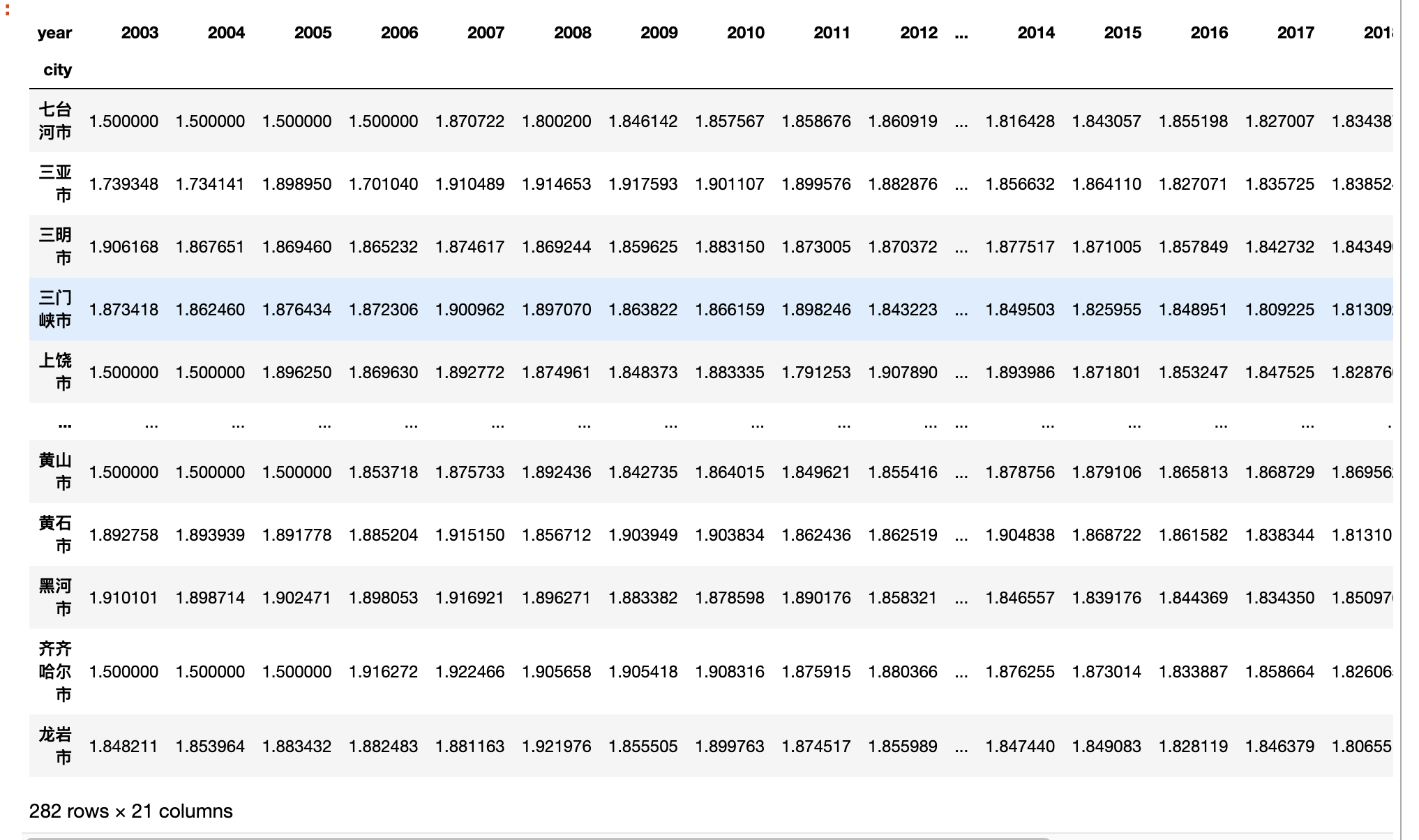
panel_data_df
Run
(282, 21)
1.3 保存数据
保存计算结果, 大家对该数据感兴趣,点击下载282city-digitalization2002-2003.csv
panel_data_df.to_csv('282city-digitalization2002-2003.csv', index=False)
二、可视化
2.1 plot_line
def plot_line(panel_df, title):
import matplotlib.pyplot as plt
import matplotlib
import scienceplots
import platform
import pandas as pd
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
import jieba
import warnings
warnings.filterwarnings('ignore')
plt.style.use(['science', 'no-latex', 'cjk-sc-font'])
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
panel_df_T = panel_df.T
panel_df_T.index = pd.to_datetime(panel_df_T.index)
ax = panel_df_T.plot(figsize=(10, 5))
# 添加图例,并指定位置和偏移
ax.legend(loc='upper right', bbox_to_anchor=(1.15, 1.05))
plt.title(title, size=15)
plt.xticks(size=12)
plt.xlabel('年份', size=13)
plt.ylabel('词频', size=13)
plt.show()
2.2 十城数字化
按照我自己对城市的感知, 1-5线城市
- 深圳市
- 杭州市 成都市 合肥市
- 青岛市 长沙市 西安市
- 哈尔滨市 石家庄市
- 衡水市
咱们看看不同级别城市的数字化词频是否有显著的差异
selected_citys = ['深圳市',
'杭州市', '成都市', '合肥市',
'青岛市', '长沙市', '西安市',
'哈尔滨市', '石家庄市',
'衡水市']
#生成面板数据
panel_data_df2 = generate_panel_data(csvf='city_report2003-2023.csv',
concept_words = digitalization_words,
selected_citys = selected_citys)
#绘图
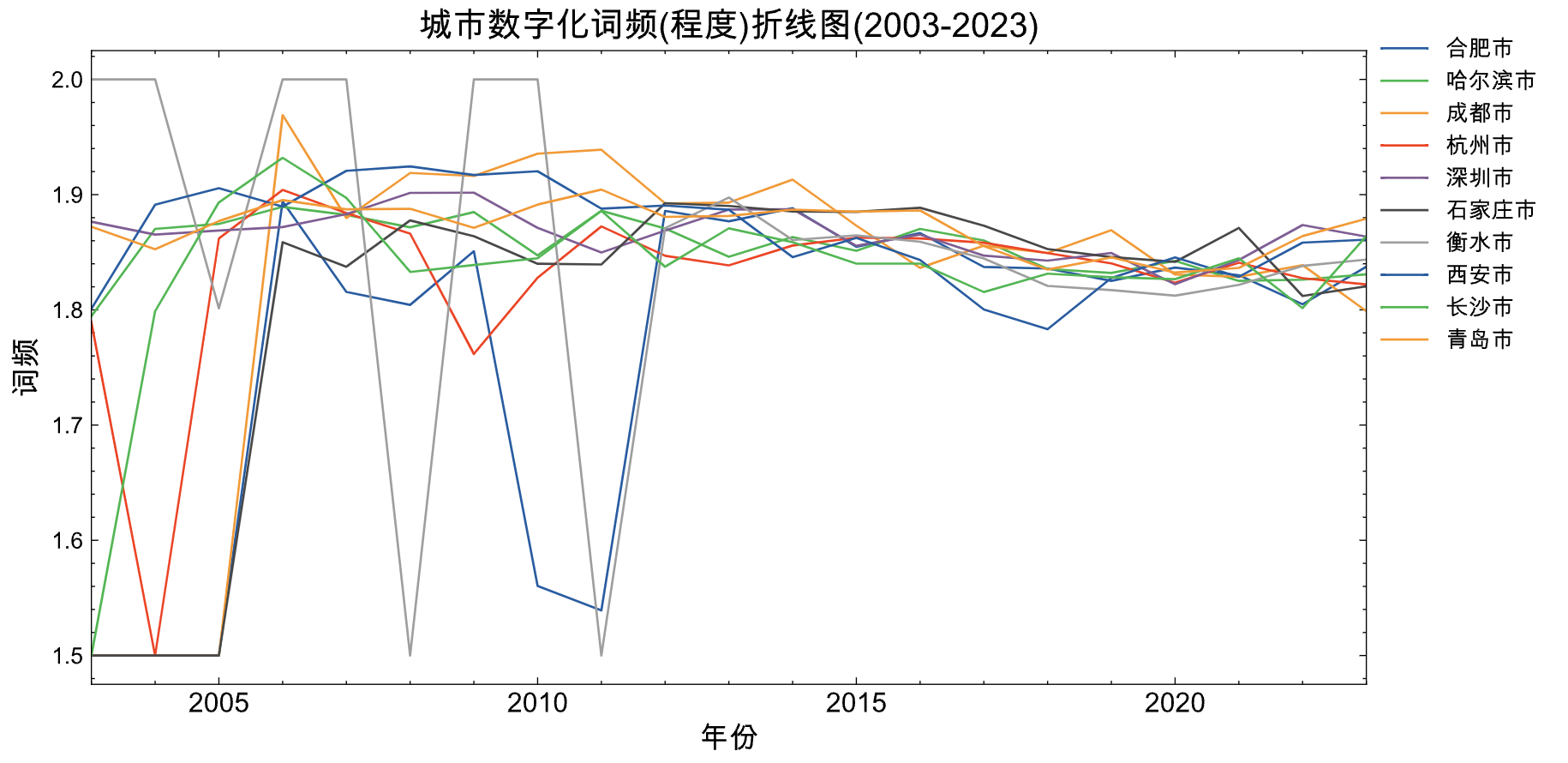
plot_line(panel_df=panel_data_df2,
title='城市数字化词频(程度)折线图(2003-2023)')
从图中可以看到
- 12年之前, 数字化词频变动较大。
- 衡水市数字化词频在2004、2007、2010是所有城市中最高的, 但是在这三个时间点之间又是局部最低点。
- 12年之后各个城市呈现下降趋势。 可能的原因并不是政府不重视数字化建设, 恰恰是数字化问题得到解决,没那么迫切,也就不太提及。
从政务数字化实现程度(从常识出发), 杭州绝对是no1。 用数字化词频高低体现数字化重视程度, 衡水曾有几个年份是十个城市中的最高点,是最重视数字化的城市。 而杭州的政府工作报告中数字化词频并不比其他地市突出,这令我很失望啊。
三、总结
之前看到一篇论文研究人民网留言板问答中的政府回复行为, 控制变量使用的是政府数字化程度。
论文使用政府工作报告数字化词语提及次数, 用来测量政府的数字化程度。
但从今天的实验看,用数字化词频测量政府数字化程度,不怎么准, 要慎重使用。
四、获取数据集
数据集100元, 加微信 372335839, 备注「姓名-学校-专业」。