
一、工商数据集概况
数据来源: 国家企业信用信息公示系统
记录条数: 2.49亿条
文件体积: 160G(解压后)
涵盖日期: 1949.10.1~2023.9.19
1.1 字段
任意csv文件的字段包括
- 企业名称
- 英文名称
- 统一社会信用代码
- 企业类型
- 经营状态
- 成立日期
- 核准日期
- 法定代表人
- 注册咨本
- 实缴资本
- 参保人数
- 公司规模
- 经营范围
- 注册地址
- 营业期限
- 纳税人识别号
- 工商注册号
- 组织机构代码
- 联系电话(脱敏)
- 邮箱(脱敏)
- 纳税人资质
- 曾用名
- 所属省份
- 所属城市
- 所属区县
- 网站链接
- 所属行业
- 登记机关
- 经度
- 纬度
数据集已经脱敏处理, 避免分享过程出现违规(法)问题。 如果你想获取手机号,商业用途, 就不要联系我了!我没有,有也不卖。
1.2 查看文件
import os
os.listdir()
Run
[
'北京.csv.gz',
'上海.csv.gz',
'南京.csv.gz',
...
'重庆.csv.gz',
]
二、实验代码
2.1 读取数据
不考虑电脑内存容量限制, 读取 石家庄市、长沙市、杭州市。如果电脑内存很小,请先阅读 推荐 | 如何处理远超电脑内存的csv文件
import pandas as pd
sjz_df = pd.read_csv('石家庄.csv.gz', compression='gzip', encoding='utf-8', low_memory=False)
cs_df = pd.read_csv('长沙.csv.gz', compression='gzip', encoding='utf-8', low_memory=False)
hz_df = pd.read_csv('杭州.csv.gz', compression='gzip', encoding='utf-8', low_memory=False)
#随机显示2条记录
sjz_df.sample(2)

2.2 记录数
石家庄.csv 企业记录数
len(sjz_df)
Run
2010163
2.3 所含字段
含有的字段有
sjz_df.columns
Index(['企业组织机构代码', '企业名称', '注册资本', '实缴资本', '纳税人识别号', '法定代表人', '企业状态', '所属行业',
'企业名称', '英文名称', '统一社会信用代码', '企业类型', '经营状态', '成立日期', '核准日期', '法定代表人',
'注册咨本', '实缴资本', '参保人数', '公司规模', '经营范围', '注册地址', '营业期限', '纳税人识别号', '工商注册号', '组织机构代码', '联系电话', '邮箱', '纳税人资质', '曾用名', '所属省份', '所属城市', '所属区县', '网站链接', '所属行业', '登记机关', '经度', '纬度'],
dtype='object')
2.4 日期转换
sjz_df['成立日期'] = pd.to_datetime(sjz_df['成立日期'])
#石家庄数据集日期范围
print(sjz_df['成立日期'].min())
print(sjz_df['成立日期'].max())
Run
1917-01-30 00:00:00
2023-09-19 00:00:00
查看成立日期为1917-01-30的信息
import datetime
sjz_df[sjz_df['成立日期']==datetime.datetime(year=1917, month=1, day=30)].to_dict()
Run
{'企业组织机构代码': {913555: '81130000MC0611518K'},
'企业名称': {913555: '中国铁路工会石家庄站委员会'},
'注册资本': {913555: '276.5万元人民币'},
'实缴资本': {913555: '-'},
'纳税人识别号': {913555: '81130000MC0611518K'},
'法定代表人': {913555: '韩海峰'},
'企业状态': {913555: '暂无'},
'所属行业': {913555: '公共管理、社会保障和社会组织'},
'统一社会信用代码': {913555: '81130000MC0611518K'},
'工商注册号': {913555: nan},
'组织机构代码': {913555: '-'},
'登记机关': {913555: '河北省总工会'},
'成立日期': {913555: Timestamp('1917-01-30 00:00:00')},
'核准日期': {913555: '1949-10-01'},
'企业类型': {913555: '-'},
'经营期限': {913555: '2019-04-01 至 2022-02-09'},
'注册所在地': {913555: nan},
'地区编码': {913555: '130105'},
'详细地址': {913555: '石家庄市新华区大桥路2号'},
'经营范围': {913555: '-'},
'参保人数': {913555: 478.0},
'企业电话': {913555: nan},
'企业座机': {913555: nan},
'企业邮箱': {913555: nan}}
三、可视化
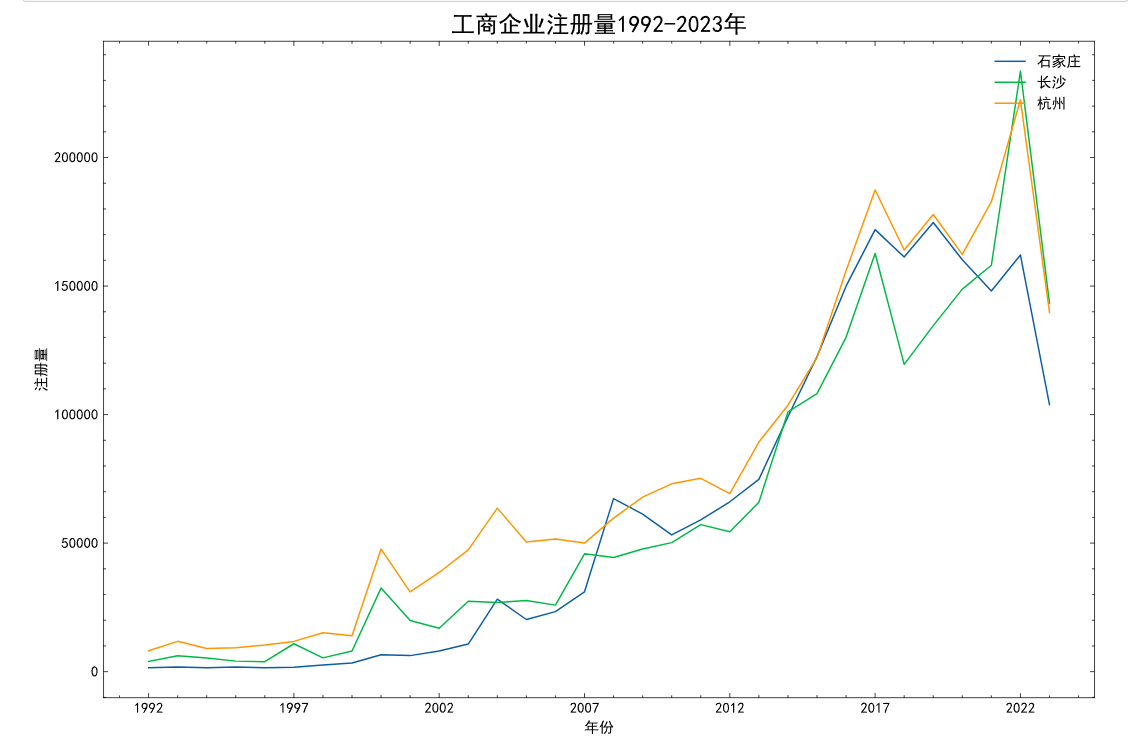
绘制一个1992-2023年的注册量折线图
import matplotlib.pyplot as plt
import matplotlib
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
import scienceplots
import platform
plt.style.use(['science', 'no-latex', 'cjk-sc-font'])
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
plt.figure(figsize=(12, 8))
years = [str(y) for y in range(1992, 2023)]
sjz_df['成立日期'].str.slice(0, 4).value_counts(ascending=True)[years].plot(label='石家庄')
cs_df['成立日期'].str.slice(0, 4).value_counts(ascending=True)[years].plot(label='长沙')
hz_df['成立日期'].str.slice(0, 4).value_counts(ascending=True)[years].plot(label='杭州')
plt.title('工商企业注册量1992-2019年', fontsize=16, color='black', ha='center')
plt.xlabel('年份')
plt.ylabel('注册量')
plt.legend(loc='upper right')
plt.show()
四、获取数据
内容为付费数据集, 100元, 加微信 372335839, 备注「姓名-学校-专业-工商数据集」