
一、数据集简介
- 数据来源: 中国政府采购网(www.ccgp.gov.cn)
- 记录数量: 3724395
- 发布时间: 1996-06-05 ~ 2024-03-07, 但主要是2015之后
数据集 100 元,购买请加微信 372335839, 备注 【姓名-学校-专业】
1. 付费数据集,100元;加微信 372335839, 备注「姓名-学校-专业」。
2. 数据是虚拟产品,一经售出,不再退还!
3. 请仔细阅读推文内容, 确认无误再加微信详谈购买事宜
二、应用
随着政府采购规模的逐步增加,中国政府采购网披露的信息越来越丰富。近年来一些学者也关 注到中国政府采购数据,但由于文本数据半结构化、高维、数据量大的特性,该数据在文本的整理、 关键变量识别与关键变量提取方面存在着不小的难度,目前而言使用该数据的研究并没有很多。
2.1 创新
姜爱华和费堃桀(2021) 手工整理了 2015-2019 年的政府采购数据,利用公告中供应商的名称与上市公司全称进行匹配,最终得到了 13 004 个企业年度观测值,发现企业获 得政府采购订单能够显著促进企业创新。
Beraja 等(2020)基 于 2013-2019 年政府采购合同,与中国人工智能企业进行名单匹配,得到 28 023 份政 府人脸识别采购合同样本,发现政府采购对人脸识别相关的人工智能专利的增长起到了推动作用。
2.2 政企关系
Fang 等(2022)利用中国政府采购网 2013-2020 年的采购公告与工商注册企业数据进行匹配,发现当本地官员处于激烈的政治竞争中时,本地政府将更少地向 竞争地区的企业进行采购,这造成了市场分割,影响了资源分配。
2.3 其他
政府采购影响企业履行企业社会责任(韩旭和武威,2021)、中国特色精准扶贫(武威等,2022)、经济 发展(武威和刘国平,2021)等。此外,还有研究单独使用政府采购数据测量经济生产生活。江鸿 泽和梁平汉(2022)基于政府采购公告整理了各地的公共视频监控系统使用情况,Liu 等(2022) 则抓取了 2013-2021 年政府采购公告,用以识别企业的政治联系。
二、查看数据
2.1 读取数据
import pandas as pd
df = pd.read_csv('政府采购公告1996-2024.3.csv.gz', compression='gzip')
#gz文件可用bandizp或winrar解压得到csv
#df = pd.read_csv('政府采购公告1996-2024.3.csv')
df['合同公告日期'] = pd.to_datetime(df['合同公告日期'])
df.head(1)

2.2 记录数
print('数据集记录数: ', len(df))
数据集记录数: 2883958
2.3 字段
数据所含字段
for col in df.columns:
print(col)
合同编号
合同名称
项目编号
项目名称
采购人(甲方)
采购人地址
采购人联系方式
供应商(乙方)
供应商地址
供应商联系方式
主要标的名称
规格型号或服务要求
主要标的数量
主要标的单价
合同金额(万元)
履约期限、地点等简要信息
采购方式
合同签订日期
合同公告日期
其他补充事宜
所属地域
所属行业
代理机构
2.4 公告日期
#数据集公告日期起止
df['合同公告日期'] = pd.to_datetime(df['合同公告日期'])
print('发布时间', df['合同公告日期'].min())
print('发布时间', df['合同公告日期'].max())
发布时间 1996-06-05 00:00:00
发布时间 2024-03-07 00:00:00
#政府采购合同公告数据,主要出现在2015年之后
df['合同公告日期'].dt.year.value_counts().sort_index()
合同公告日期
1996 1
2000 1
2002 2
2004 7
2008 5
2009 3
2010 2
2011 13
2012 3
2013 4
2014 24
2015 15543
2016 42195
2017 94193
2018 154922
2019 151181
2020 187874
2021 549078
2022 1060710
2023 1355749
2024 112885
Name: count, dtype: int64
梁平汉和郭宇辰(2023) 认为 2015年财政部相关采购信息发布文件出台之后采购公告上传率大幅上升至80%以上,因此采用2015年以后的中国政府采购网数据进行研究更为合适。
2.4 甲(乙)方人数
#甲方乙方数量
#甲方乙方数量
print('采购人(甲方)数: ', df['采购人'].nunique())
print('供应商(乙方)数: ', df['供应商'].nunique())
采购人(甲方)数: 234082
供应商(乙方)数: 499943
三、实验代码
3.1 是否含某(类)词
根据公告中是否出现某(类)词,可以提起一些指标。例如 Beraja 等(2020)基于 2013-2019 年政府采购合同,与中国人工智能企业进行名单匹配,得到 28 023 份政府人脸识别采购合同样本。 本文仅简单示范, 以 人工智能 相关词为例
df['合同名称'].fillna('').str.contains('人工智能|自然语言处理|自动驾驶|AI|ai')
Run
0 False
1 False
2 False
3 False
4 False
...
3724390 False
3724391 False
3724392 False
3724393 False
3724394 False
Name: 合同名称, Length: 3724395, dtype: bool
#AI相关公告的数量
df['合同名称'].fillna('').str.contains('人工智能|自然语言处理|自动驾驶|AI|ai').sum()
Run
1323
#显示匹配到的与 AI 有关的【合同名称】
df[df['合同名称'].fillna('').str.contains('人工智能|自然语言处理|自动驾驶|AI|ai')]['合同名称']
Run
1129 贵州大学人工智能研究院建设项目采购合同
4935 龙岩初级中学人工智能创客实验室设备货物类采购项目合同\n (macrodatas.cn)
12231 中国医学科学院系统医学研究院人工智能高性能计算设备采购合同协议书
13171 双高基于AIoT轨道交通智慧运维环境信号检测分析设备购置(二次)\n\n微信公众号“马克 数据网”
16921 广州国际生物岛自动驾驶新能源环卫作业创新试点服务采购项目
...
3708596 榆林市教育技术中心人工智能助推教师队伍建设-教师发展智慧管理平台建设项目合同
3708922 邢台市信都区“人工智能公共技术服务平台”项目一标段数字教育、数字文旅采购合同\n\n ()
3709875 吴忠市第三中学南湖校区AI课堂教学行为分析评测系统及智慧教室设备采购项目系统集成服务合同
3712051 人工智能与机器人领域创新成果产业化成熟度评价
3724277 民乐县现代农业投资有限责任公司民乐县人工智能一二三产业融合功能区食用菌菌棒生产项目 ()
Name: 合同名称, Length: 1323, dtype: object
3.2 构建省份字段
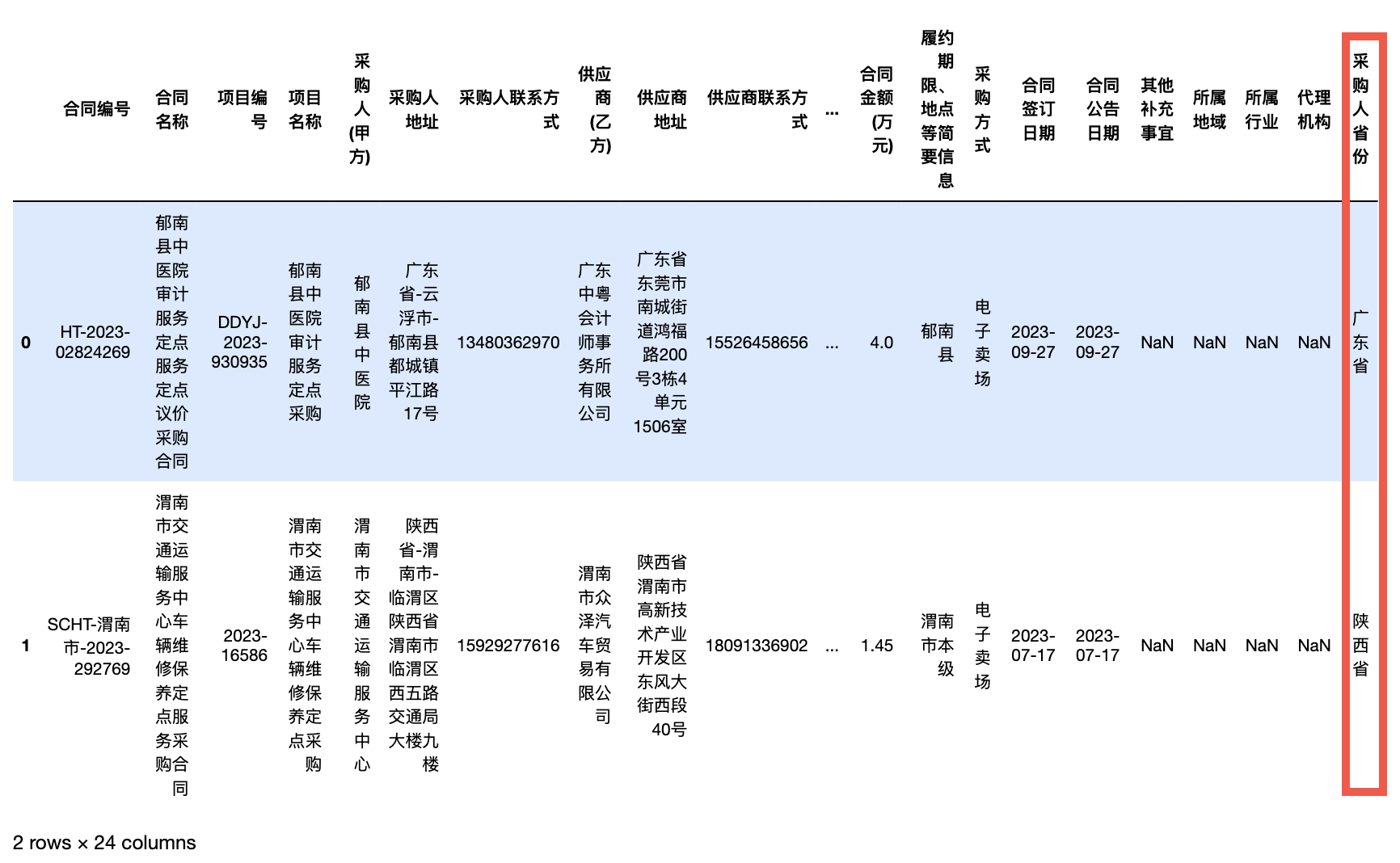
数据集中有 采购人地址、采购人(甲方) 两个地址字段,我们以 采购人(甲方) 为例,构建 采购人省份 字段。 注意: 经过测试,使用cpca库提取省份信息, 两种方式提取省份信息缺失率依次是 24.8%、 7%, 因此我们决定采用 采购人(甲方) 来提取省份。
import cpca
provs_df = cpca.transform(df['采购人(甲方)'])
df['采购人省份'] = cpca.transform(df['采购人(甲方)'])['省']
df['采购人省份'] = df['采购人省份'].fillna('').apply(lambda k: re.sub('自治区|特别行政区', '', k))
df.head(2)
3.3 按省分组查看记录量
假设 采购人省份 构建的准确的话, 就可以分组查看每个省的记录量。 df.groupby(‘采购人省份’)
for prov, prov_df in df.groupby('采购人省份'):
print(prov, len(prov_df))
Run
267312 (未知省份,cpca缺失字段,占比大概7%)
上海市 29493
云南省 49789
内蒙古 480459
北京市 71869
台湾省 93
吉林省 14219
四川省 155028
天津市 10734
宁夏回族 76783
安徽省 44133
山东省 14634
山西省 5784
广东省 1349039
广西壮族 12534
新疆维吾尔 8000
江苏省 28655
江西省 8949
河北省 203761
河南省 8159
浙江省 12158
海南省 38603
湖北省 6156
湖南省 11300
甘肃省 289772
福建省 97527
西藏 2558
贵州省 2599
辽宁省 34547
重庆市 58673
陕西省 55478
青海省 22441
香港 80
黑龙江省 253076
import matplotlib.pyplot as plt
import matplotlib
import scienceplots
import platform
import pandas as pd
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
import jieba
import warnings
warnings.filterwarnings('ignore')
plt.style.use(['science', 'no-latex', 'cjk-sc-font'])
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
prov_volumes = []
for prov, prov_df in df.groupby('采购人省份'):
prov_volumes.append({'prov': prov, 'volume': len(prov_df)})
prov_volumes_df = pd.DataFrame(prov_volumes)
prov_volumes_df.set_index('prov').sort_values('volume', ascending=False).plot(kind='bar', figsize=(10, 4))
plt.title('政府采购数量(采购人按省)', size=15)
plt.xticks(size=10, rotation=45)
plt.xlabel('省份', size=13)
plt.ylabel('采购公告数量', size=13)
plt.show()
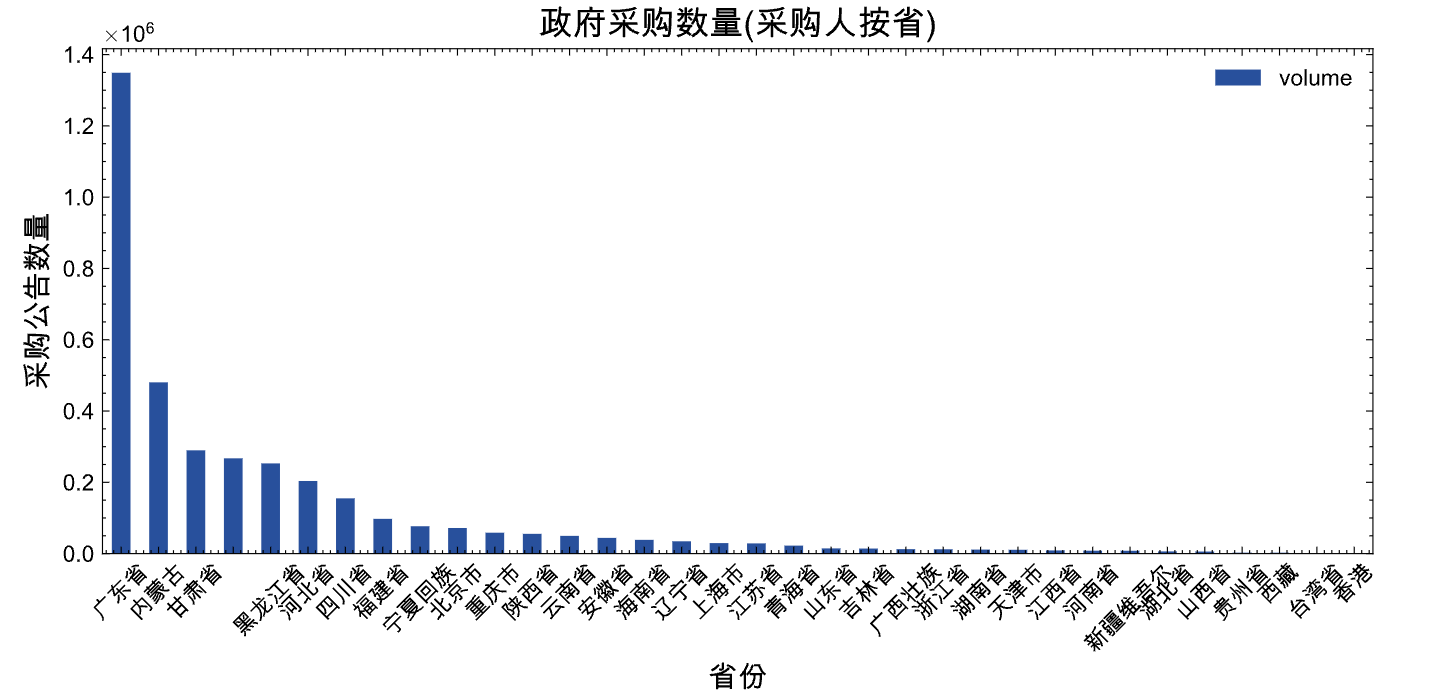
采购按省, 最多的几个省份依次是广东、内蒙、甘肃、黑龙江等。 甘肃和黑龙江之间有个空白, 这是因为根据采购人(甲方)使用cpca提取省份信息时,有7%记录是缺失的。
三、相关研究
相关研究近期文献
[1]周亚虹,蒲余路,陈诗一等.政府扶持与新型产业发展——以新能源为例[J].经济研究,2015,50(06):147-161.
[2]武威,刘国平.政府采购与经济发展:转型效应与协同效应——基于产业结构升级视角[J].财政研究,2021(08):77-90.
[3]孙薇,叶初升.政府采购何以牵动企业创新——兼论需求侧政策“拉力”与供给侧政策“推力”的协同[J].中国工业经济,2023(01):95-113.
[4]姜爱华,费堃桀,张鑫娜.政府采购、营商环境与企业创新——基于A股上市公司的经验证据[J].中央财经大学学报,2022(09):3-15.
[5]梁平汉, 郭宇辰. 中国政府采购公告数据的使用和潜在问题[J]. 产业经济评论, 2023, (01): 68-80.
四、获取数据
1. 付费数据集,100元;加微信 372335839, 备注「姓名-学校-专业」。
2. 数据是虚拟产品,一经售出,不再退还!
3. 请仔细阅读推文内容, 确认无误再加微信详谈购买事宜