pandas是最有用的Python数据分析库, 两个数据类型DataFrame和Series,值的我们反复接触、学习和实验,逐渐的将pandas独特的语法掌握。
DataFrame是什么?#
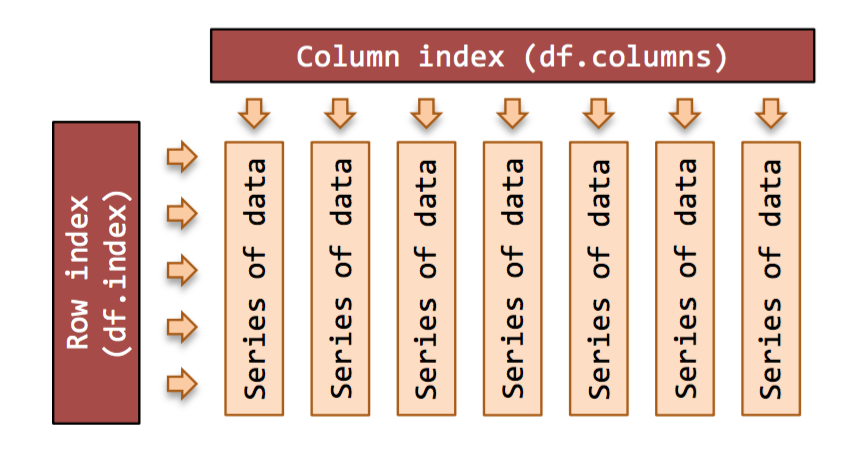
DataFrame是一种二维数据类型, 跟 Excel中的数据结构差不多, 即
每列(行),看做一个序列Series,在pandas中就是pd.Series类型的数据, 由很多pd.Sereis组成的数据就是DataFrame。
一、创建DataFrame#
创建DataFrame有两种方式
- 使用pd.read_csv()/ pd.read_excel() 从csv、xlsx等文件导入, 得到DataFrame
- 使用pd.DataFrame()函数构造DataFrame
import pandas as pd
data = {'name': ['David', 'Mary', 'Jessica', 'John'],
'age': ['25', '30', '31', '20'],
'gender': ['male', 'female', 'female', 'male']}
df = pd.DataFrame(data)
df
|
name |
age |
gender |
| 0 |
David |
25 |
male |
| 1 |
Mary |
30 |
female |
| 2 |
Jessica |
31 |
female |
| 3 |
John |
20 |
male |
二、选中某行(列)#
df.loc[row, :] 选中第row行所有数据df.loc[row:row, :] 选中第row行所有数据df.loc[row1: row2, ] 选中从row1至row2行的所有数据df.loc[:, col] 选中第col列所有数据df.loc[:, [col]] 选中第col列所有数据df.loc[:, cols] 选中cols列的所有数据
#选中第二行所有数据,返回结果为Series
df.loc[2, :]
name Jessica
age 31
gender female
Name: 2, dtype: object
#选中第二行所有数据,返回结果为DataFrame
df.loc[2:2, :]
|
name |
age |
gender |
| 2 |
Jessica |
31 |
female |
#选中某列所有数据,返回结果为Series
df.loc[:, 'gender']
0 male
1 female
2 female
3 male
Name: gender, dtype: object
#选中某列所有数据,返回结果为DataFrame
df.loc[:, ['gender']]
|
gender |
| 0 |
male |
| 1 |
female |
| 2 |
female |
| 3 |
male |
#选中某几列所有数据,返回结果为DataFrame
df.loc[:, ['age', 'gender']]
|
age |
gender |
| 0 |
25 |
male |
| 1 |
30 |
female |
| 2 |
31 |
female |
| 3 |
20 |
male |
三、新建某行(列)#
df[colname] = col_data 新增一列(字段)数据df.loc[row] = row_data 新增一条行(记录)数据
#复制实验数据
df2 = df.copy()
df2
|
name |
age |
gender |
| 0 |
David |
25 |
male |
| 1 |
Mary |
30 |
female |
| 2 |
Jessica |
31 |
female |
| 3 |
John |
20 |
male |
#新增nation字段列
df2['nation'] = ['US', 'UK', 'UK', 'US']
df2
|
name |
age |
gender |
nation |
| 0 |
David |
25 |
male |
US |
| 1 |
Mary |
30 |
female |
UK |
| 2 |
Jessica |
31 |
female |
UK |
| 3 |
John |
20 |
male |
US |
#新建(增)一行数据
df2.loc[4] = ['Robert', 22, 'male', 'US']
df2
|
name |
age |
gender |
nation |
| 0 |
David |
25 |
male |
US |
| 1 |
Mary |
30 |
female |
UK |
| 2 |
Jessica |
31 |
female |
UK |
| 3 |
John |
20 |
male |
US |
| 4 |
Robert |
22 |
male |
US |
四、删除#
- df.drop_duplicates() 删除重复的数据
- df.drop() 删除某行(列)
df3 = df.copy()
df3.loc[4] = ['John', 20, 'male']
df3
|
name |
age |
gender |
| 0 |
David |
25 |
male |
| 1 |
Mary |
30 |
female |
| 2 |
Jessica |
31 |
female |
| 3 |
John |
20 |
male |
| 4 |
John |
20 |
male |
# 根据name字段删除重复的数据
#inplace=True,操作后会修改df3原始数据
#df3.drop_duplicates(inplace=True, subset='name')
df3.drop_duplicates(subset='name')
|
name |
age |
gender |
| 0 |
David |
25 |
male |
| 1 |
Mary |
30 |
female |
| 2 |
Jessica |
31 |
female |
| 3 |
John |
20 |
male |
#删除某行(索引值)的数据
#inplace=True,操作后会修改df3原始数据
#df3.drop(1, inplace=True)
df3.drop(4)
|
name |
age |
gender |
| 0 |
David |
25 |
male |
| 1 |
Mary |
30 |
female |
| 2 |
Jessica |
31 |
female |
| 3 |
John |
20 |
male |
#删除gender字段列
#inplace=True,操作后会修改df3原始数据
#df3.drop('gender', axis=1, inplace=True)
df3.drop('gender', axis=1)
|
name |
age |
| 0 |
David |
25 |
| 1 |
Mary |
30 |
| 2 |
Jessica |
31 |
| 3 |
John |
20 |
| 4 |
John |
20 |
五、行列重命名#
使用 df.rename() 重命名dataframe
|
name |
age |
gender |
| 0 |
David |
25 |
male |
| 1 |
Mary |
30 |
female |
| 2 |
Jessica |
31 |
female |
| 3 |
John |
20 |
male |
#重命名 字段(列)名
df4.rename(columns = {'gender': 'sex'}, inplace=True)
df4
|
name |
age |
sex |
| 0 |
David |
25 |
male |
| 1 |
Mary |
30 |
female |
| 2 |
Jessica |
31 |
female |
| 3 |
John |
20 |
male |
# 重命名行索引index
df4.rename(index = {0: 'a',
1:'b',
2:'c',
3:'c'})
|
name |
age |
gender |
| a |
David |
25 |
male |
| b |
Mary |
30 |
female |
| c |
Jessica |
31 |
female |
| c |
John |
20 |
male |
六、替换#
df5 = pd.DataFrame({"Student1":['OKs','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
df5
|
Student1 |
Student2 |
Student3 |
| 0 |
OKs |
Perfect |
Acceptable |
| 1 |
Awful |
Awful |
Perfect |
| 2 |
Acceptable |
OK |
Poor |
# 将评级单词改为对应数字序列
df5.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'],
[0, 1, 2, 3, 4])
|
Student1 |
Student2 |
Student3 |
| 0 |
OKs |
4 |
3 |
| 1 |
0 |
0 |
4 |
| 2 |
3 |
2 |
1 |
# 将评级单词改为对应数字序列
# 使用正则表达式匹配OK为2
df5.replace(['Awful', 'Poor', 'OK*', 'Acceptable', 'Perfect'],
[0, 1, 2, 3, 4],
regex=True)
|
Student1 |
Student2 |
Student3 |
| 0 |
2 |
4 |
3 |
| 1 |
0 |
0 |
4 |
| 2 |
3 |
2 |
1 |
七、 识别日期#
import pandas as pd
#自动识别日期数据
pd.read_csv('yourFile', parse_dates=True)
#或指定日期所在列的字段名
pd.read_csv('yourFile', parse_dates=['columnName'])
#指定日期字段的日期格式进行解析
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
八、保存#
df.to_csv('myDataFrame.csv', encoding='utf-8')
df.to_excel('myDataFrame.xlsx')
广而告之#
