
词嵌入方法(word2vec、glove等)可以将每个词的语义映射到n维空间,在n维空间中,词语间距离远近可以表征语义的远近。Kusner等人(2015)提出词移距离(word mover’s distance, 后文用WMD缩写代替)借助词语向量语义距离,实现两文档间的相似度计算,距离越小,相似度越高。在会计领域中的应用可以用来度量问答场景的答非所问的程度。
WMD基础
有两个文档
doc1 = "Obama speaks to the media in Illinois"
doc2 = "The President greets the press in Chicago."词向量一般是高(n)维空间,这里把n压缩到2维空间,使用matplotlib绘图。两个文档中重要的词语彼此之间存在语义相似度,
# Image from https://vene.ro/images/wmd-obama.png
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread('img/wmd-obama.png')
imgplot = plt.imshow(img)
plt.axis('off')## (-0.5, 2397.5, 1327.5, -0.5)plt.show()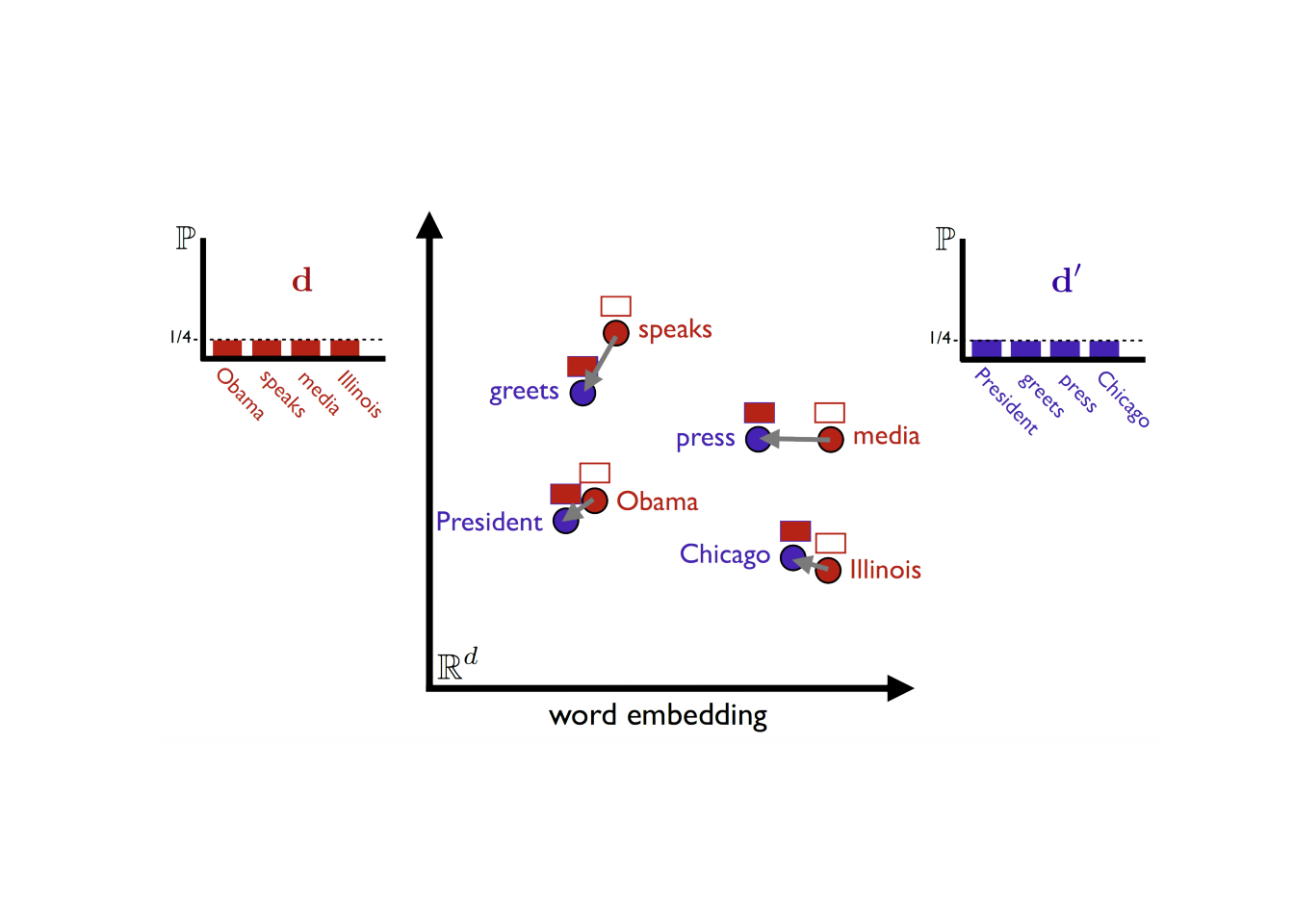
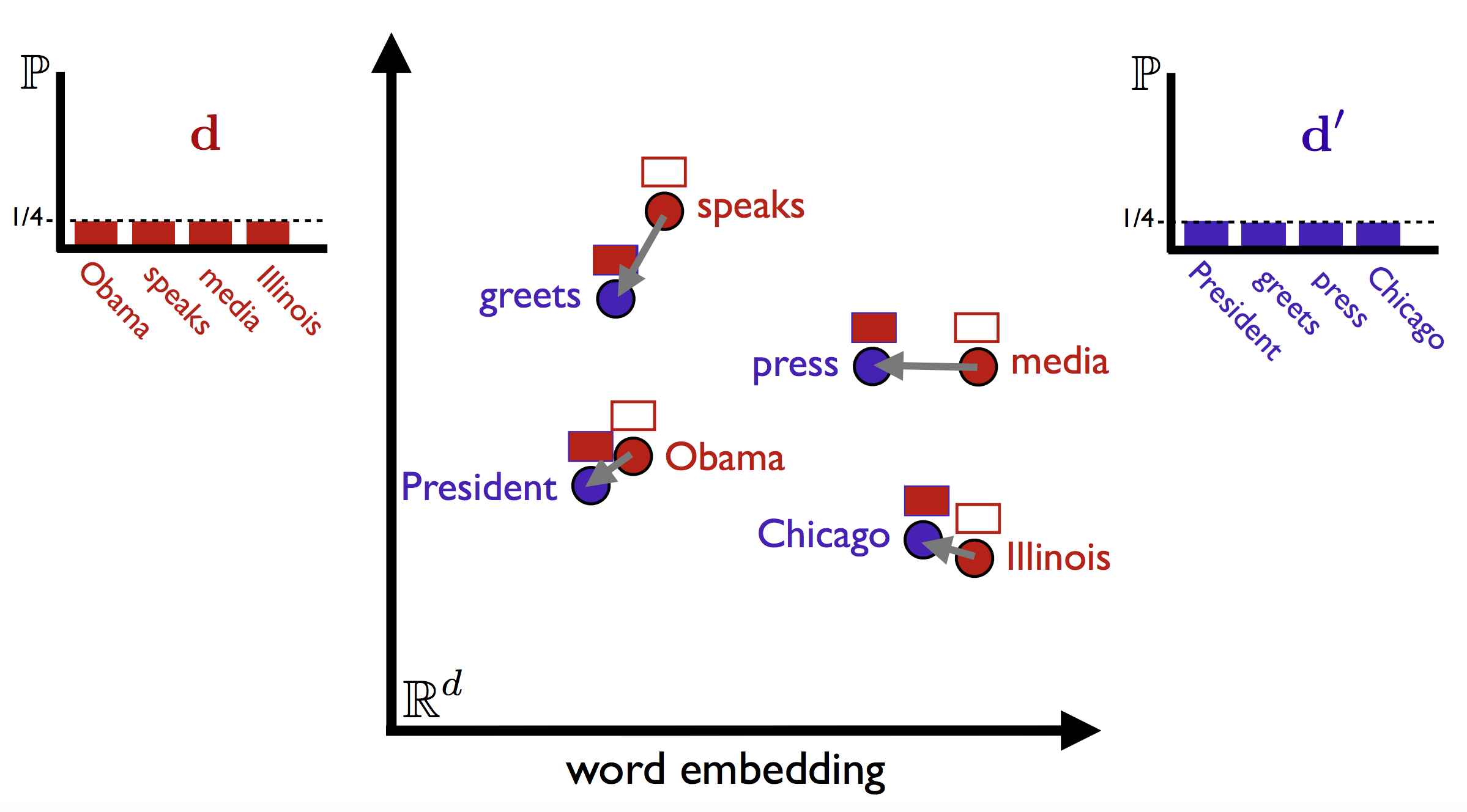
计算WMD步骤
- 剔除文档中停止词,如the、a等无信息量词
- 导入预训练好的词嵌入(word2vec)模型(网上资源比较多,如果数据量很大,也可以自己使用gensim训练自己的词向量)
- 计算WMD
from nltk.corpus import stopwords
from nltk import download
download('stopwords') # Download stopwords list.
stop_words = stopwords.words('english')
def preprocess(sentence):
return [w for w in sentence.lower().split() if w not in stop_words]
doc1 = "Obama speaks to the media in Illinois"
doc2 = "The President greets the press in Chicago."
doc1 = preprocess(doc1)
doc2 = preprocess(doc2)
print(doc1)
print(doc2)Run
['obama', 'speaks', 'media', 'illinois']
['president', 'greets', 'press', 'chicago.']如果运行代码出现nltk问题,可以观看视频 https://www.bilibili.com/video/BV14A411i7DB
下载谷歌新闻预训练模型(word2vec-google-news-300) ,这里可以使用我提供的百度网盘
链接:https://pan.baidu.com/s/1yzGLcMsZl3u1zigTHLdc2Q 提取码:l63f
这里需要
from gensim.models import KeyedVectors
w2v_model = KeyedVectors.load('GoogleNews-vectors-negative300.bin.gz')
wmd = w2v_model.wmdistance(doc1, doc2)
print('distance :{wmd}'.format(wmd=wmd))Run
distance :0.8867237050133944参考文献
- Kusner, Matt J., Yu Sun, Nicholas I. Kolkin and Kilian Q. Weinberger. “From Word Embeddings To Document Distances.” ICML (2015).
- https://radimrehurek.com/gensim/auto_examples/tutorials/run_wmd.html